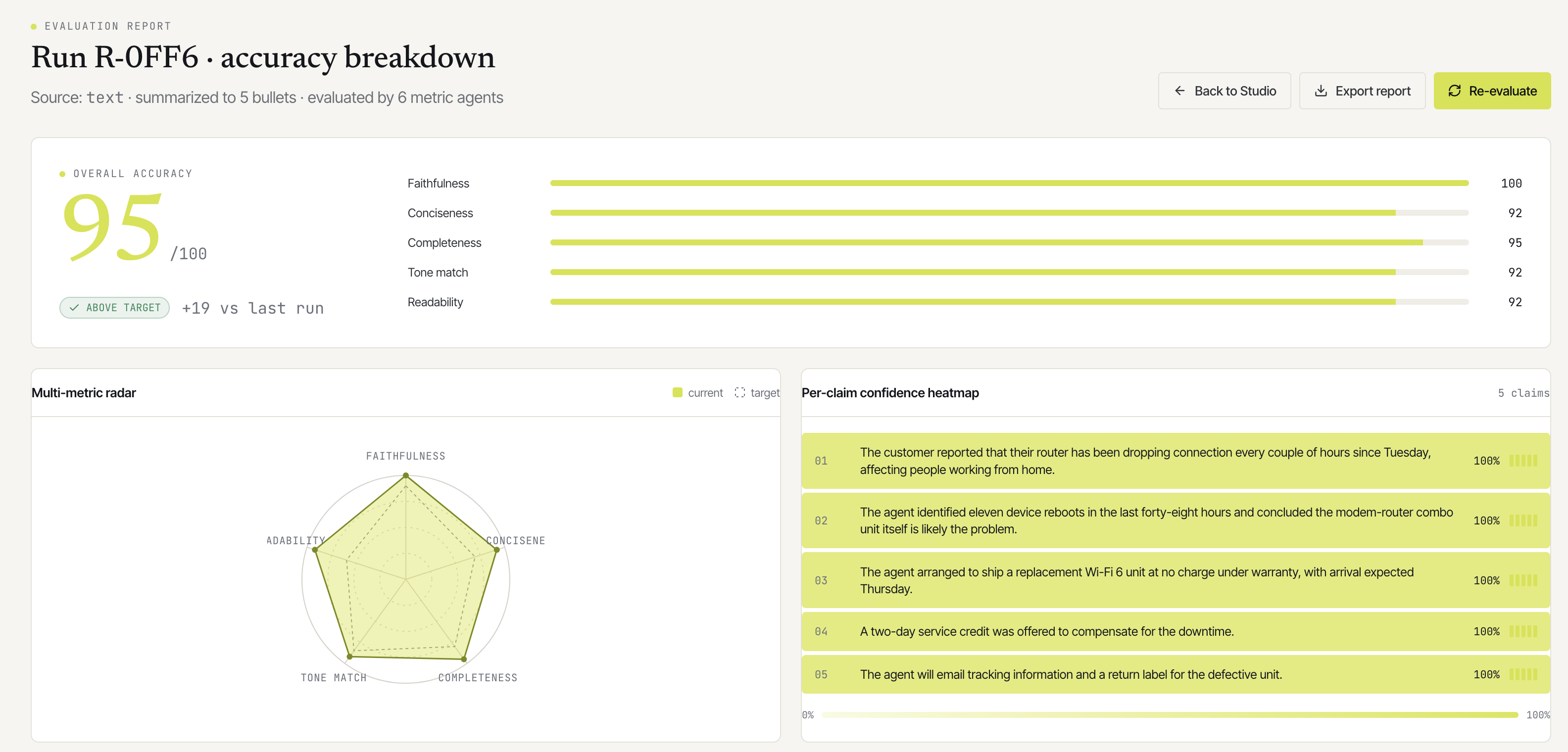
AI-as-judge: extending Synapse's evaluator
My previous post on Synapse covered the six-agent pipeline that produces the summary. This one is about the other six agents, the ones that score it. Honestly,…
Read more →Engineering leadership · AI · the long game
By Ram Chevendra — Senior Software Engineering Manager. I write about engineering leadership, agentic AI in the enterprise, and the craft of staying technical as a leader.

My previous post on Synapse covered the six-agent pipeline that produces the summary. This one is about the other six agents, the ones that score it. Honestly,…
Read more →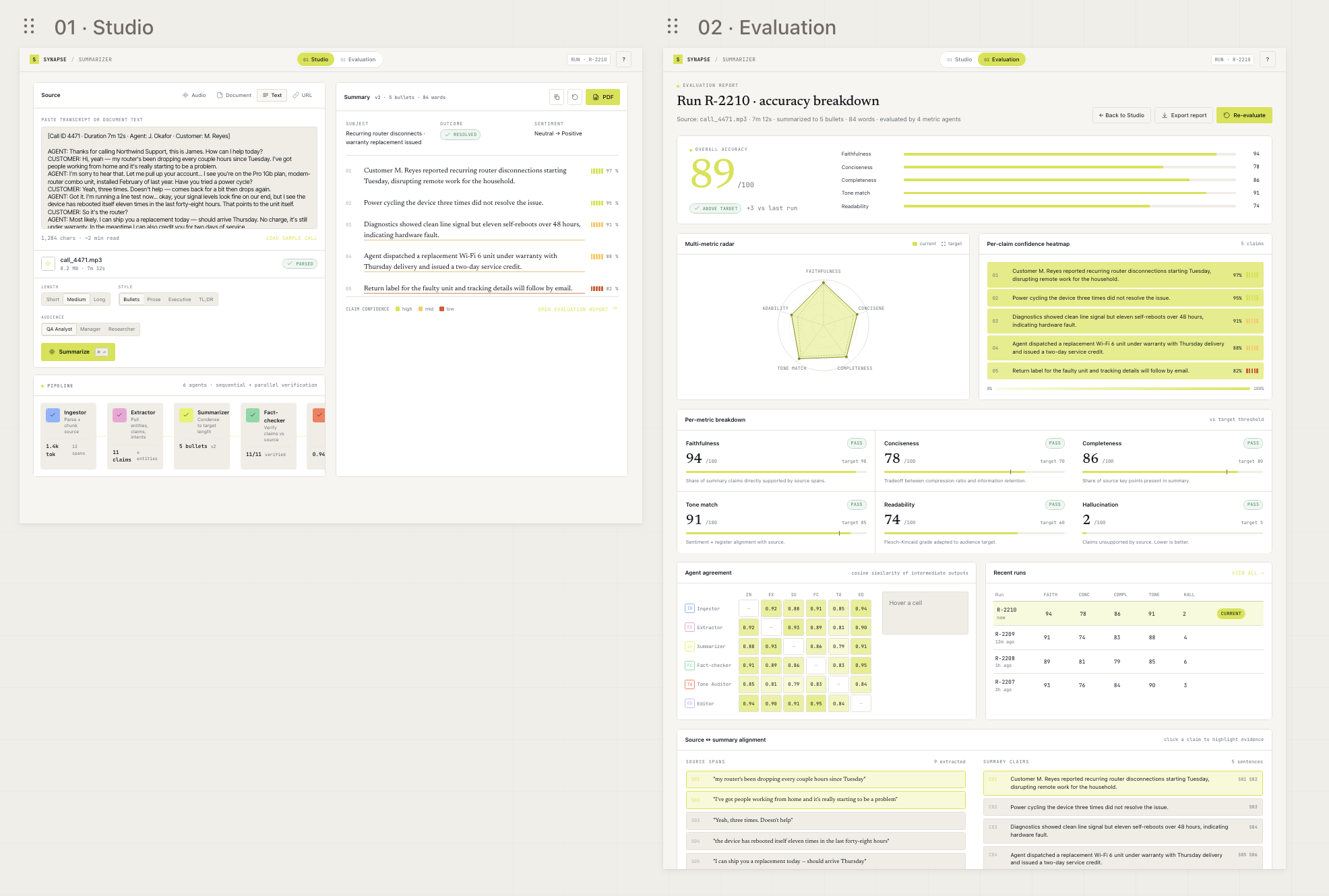
Synapse: A multi-agentic summarizer and evaluator I built Synapse over a few weekends to scratch two itches at once. The first was a real frustration: I keep e…
Read more →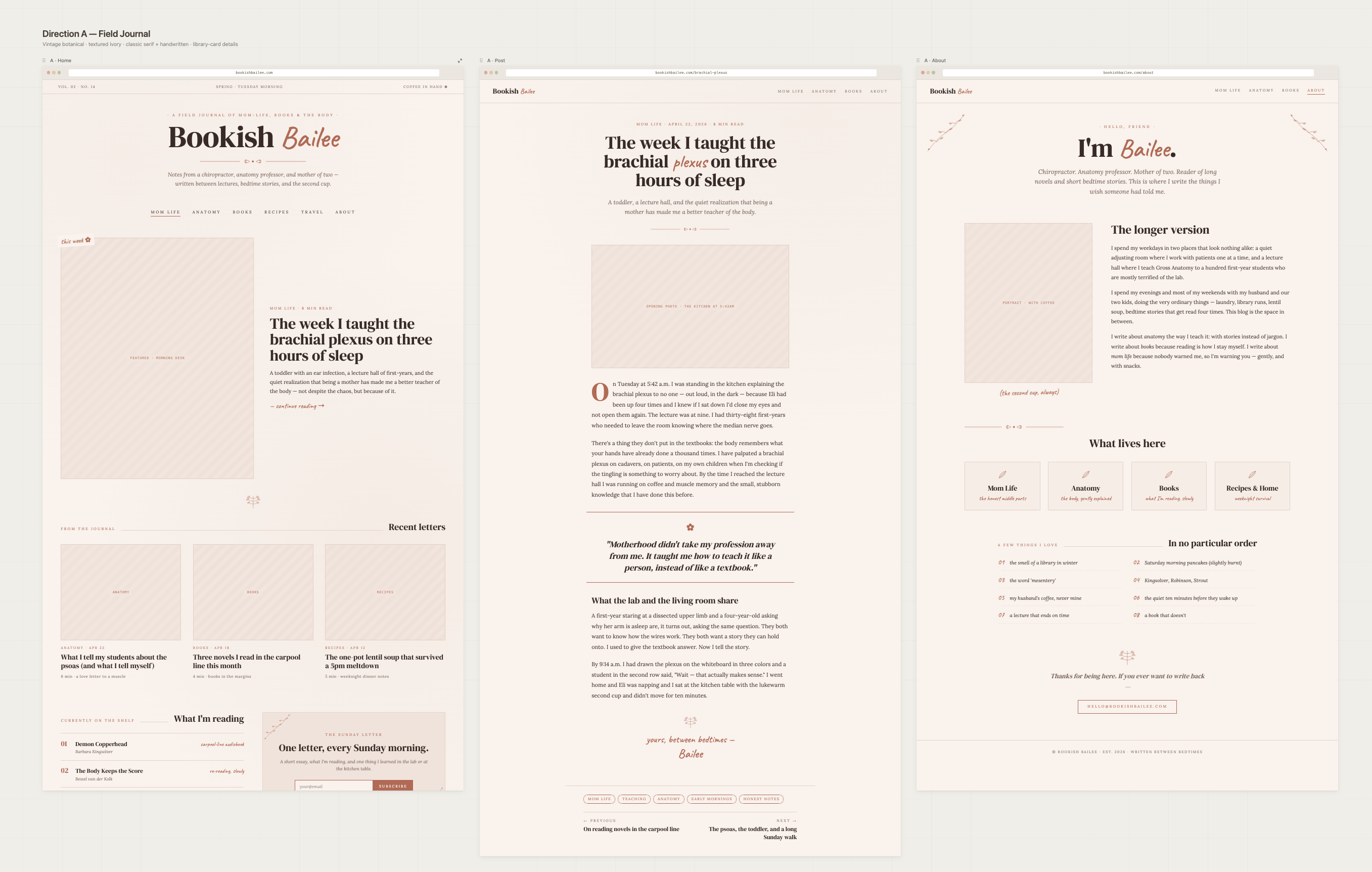
Last weekend, I designed and shipped a production blog from scratch for my wife in a few hours. I'm not a designer. I don't run a UX practice. I haven't touche…
Read more →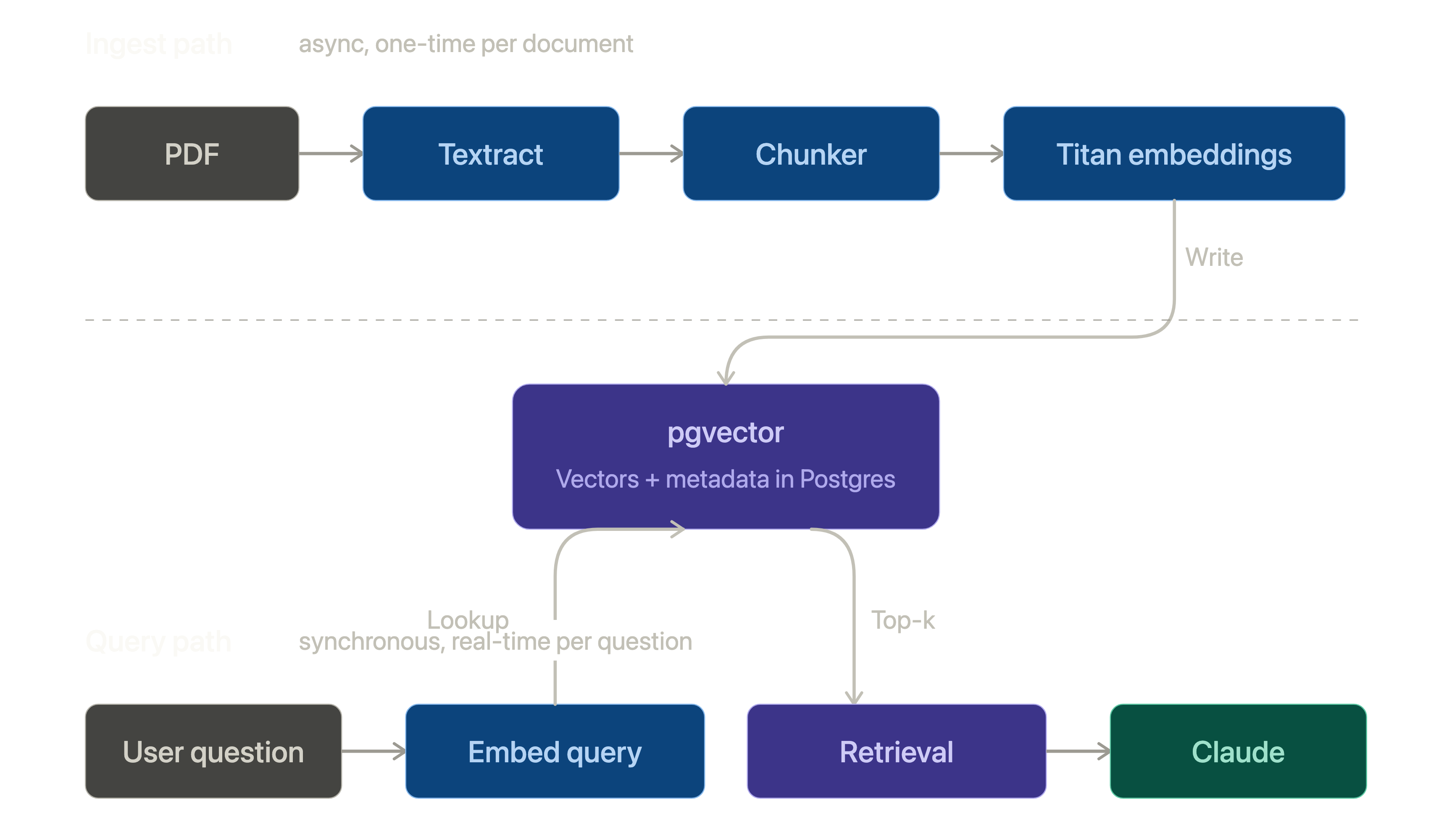
If you've ever tried to make a pile of PDFs queryable actually queryable, not just searchable by filename you've run into the same wall the rest of us have. OC…
Read more →
Five years ago, taking an idea from a whiteboard sketch to a deployed, production-grade application was measured in weeks or months. Today, for the right kind o…
Read more →Management · teams · the craft
What I’ve learned managing engineers, building teams, and balancing strategy with shipping.
Read leadership posts →Off the clock · life · the longer view
Notes outside the day job — books, family, reflections, and things that don’t fit anywhere else.
Read personal essays →