The views expressed in this post are my own and do not represent those of any current or past employer.
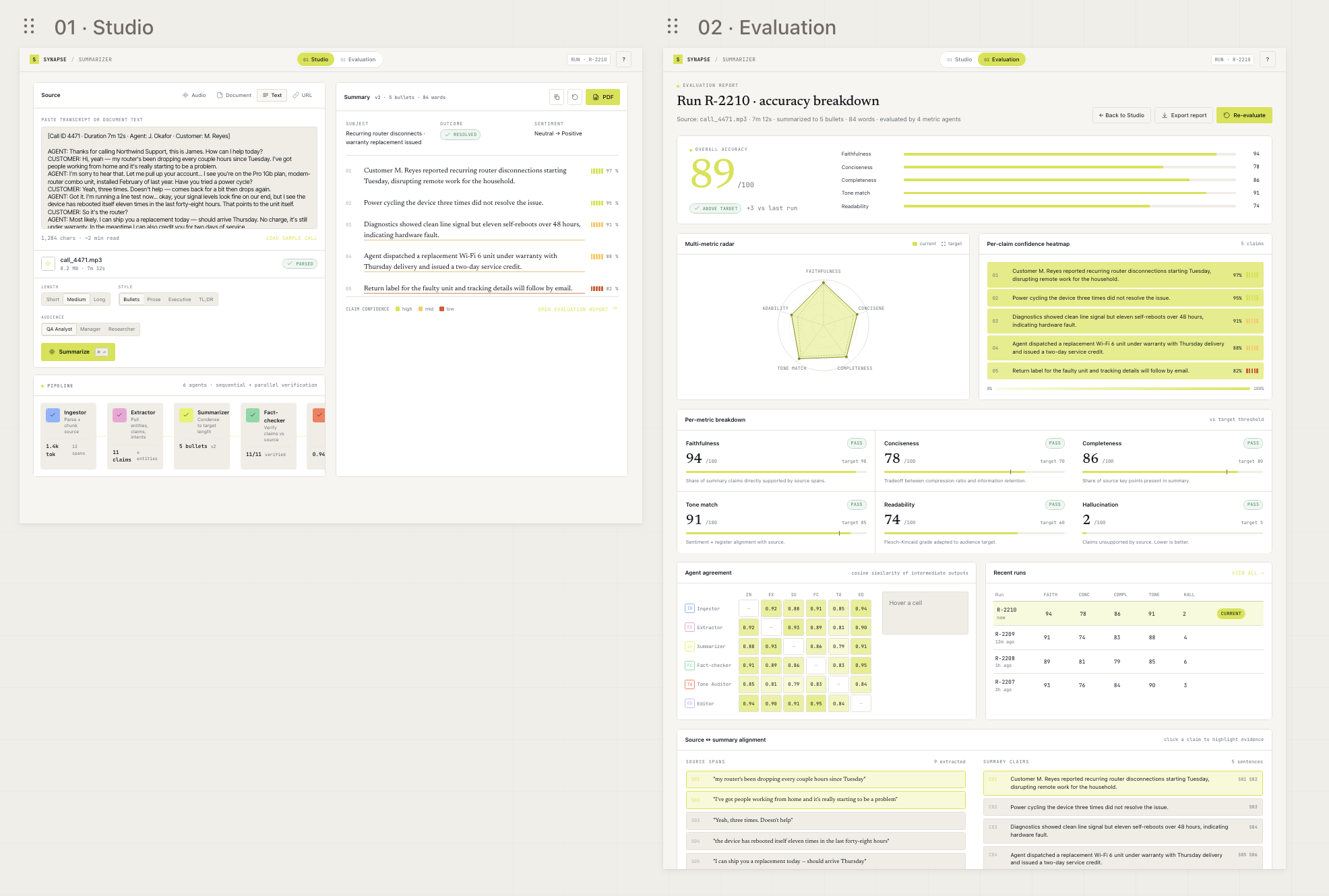
My previous post on Synapse covered the six-agent pipeline that produces the summary. This one is about the other six agents, the ones that score it.
Honestly, those judges are doing some of the most underappreciated work in the system. After an evening with Chapter 3 of Chip Huyen’s AI Engineering (evaluation methodology), I came away with a clearer view of what I built well, what I got wrong, and what I want to ship next.
This isn’t a book review. Go read the book; it’s worth it. These are just my working notes on what I’m changing because of it.
The AI-as-judge boom, and what’s missing from it
Every new agent product has an eval pipeline now. Pick a launch announcement from the last six months and there’ll be a slide with a bar chart titled “Faithfulness,” “Helpfulness,” or “Quality.” Look at the small print and almost all of those scores came from another LLM scoring the output.
That’s a useful shift. Before AI-as-judge, you had two options: write golden answers by hand (slow, doesn’t scale), or use lexical metrics like BLEU/ROUGE that correlate poorly with anything a human cares about. AI judges sit in the middle. They’re fast, cheap, and in principle able to assess subjective qualities like tone or relevance.
But here’s the weird part. We’ve poured hundreds of billions into building the models that generate text and a relatively tiny amount into the models that judge it. The judges are almost always off-the-shelf frontier models being asked to do an eval job they weren’t trained for. Specialized eval-tuned models exist (JudgeLM, PRISM, PandaLM, Patronus’ Glider) but almost nobody uses them. The reason is partly chicken-and-egg: to train a judge you need a labeled preference dataset, which requires human eval, which is the thing you were trying to avoid.
So we end up using the same general-purpose hammer for every job. It mostly works. It also fails in specific, repeatable ways. Knowing which ones is the difference between an eval pipeline that improves the product and one that flatters it.
Why we reach for AI judges at all
Human evaluation, the actual gold standard, is too expensive to ship at product scale.
If you go to a labeling vendor and ask for one human to rate one summary on six metrics with short rationales, you’re looking at somewhere between $1 and $5 per item for decent-quality work, plus QA passes for the labelers themselves. A single Synapse-sized run, with a 5-sentence summary and 6 metrics, would be roughly $5, multiplied by however many runs a real product makes per day. Even a small internal tool hits five figures monthly very quickly. Time per item is hours to days end-to-end.
AI judges are pennies and seconds. For Synapse, each Haiku judge call is well under a cent and returns in three to seven seconds. Six concurrent judge calls cost less than a vending-machine coffee.
And the quality gap, while real, is closing. Zheng et al’s “MT-Bench” paper (the one Chip cites) shows GPT-4 agreement with human raters in the 80%+ range on most tasks, which is roughly in line with the inter-human agreement rate on the same tasks. Two humans rating the same summary disagree about a fifth of the time. The AI judge isn’t “as good as a human.” It’s differently inconsistent, in ways you can characterize and partially correct for.
That’s the practical reality in Synapse: AI judges are the only way eval ships at all. They’re only useful if you know exactly where they fail.
Strong judge or weak judge, and where Haiku fits
The book lays out the tradeoff cleanly. A strong judge (Opus, GPT-4, the largest you can afford) has higher human agreement, handles subtle distinctions better, and is harder to fool with adversarial inputs. It’s also expensive and slow. A weak judge (Haiku, smaller models, distilled judges) is faster and cheaper, but noisier. The variance across runs is higher and edge cases get missed.
Chip’s recommendation maps cleanly to product constraints: use weak judges by default, escalate to strong judges for adjudication when weak judges disagree or report low confidence. Most calls stay cheap; borderline cases get the expensive pass.
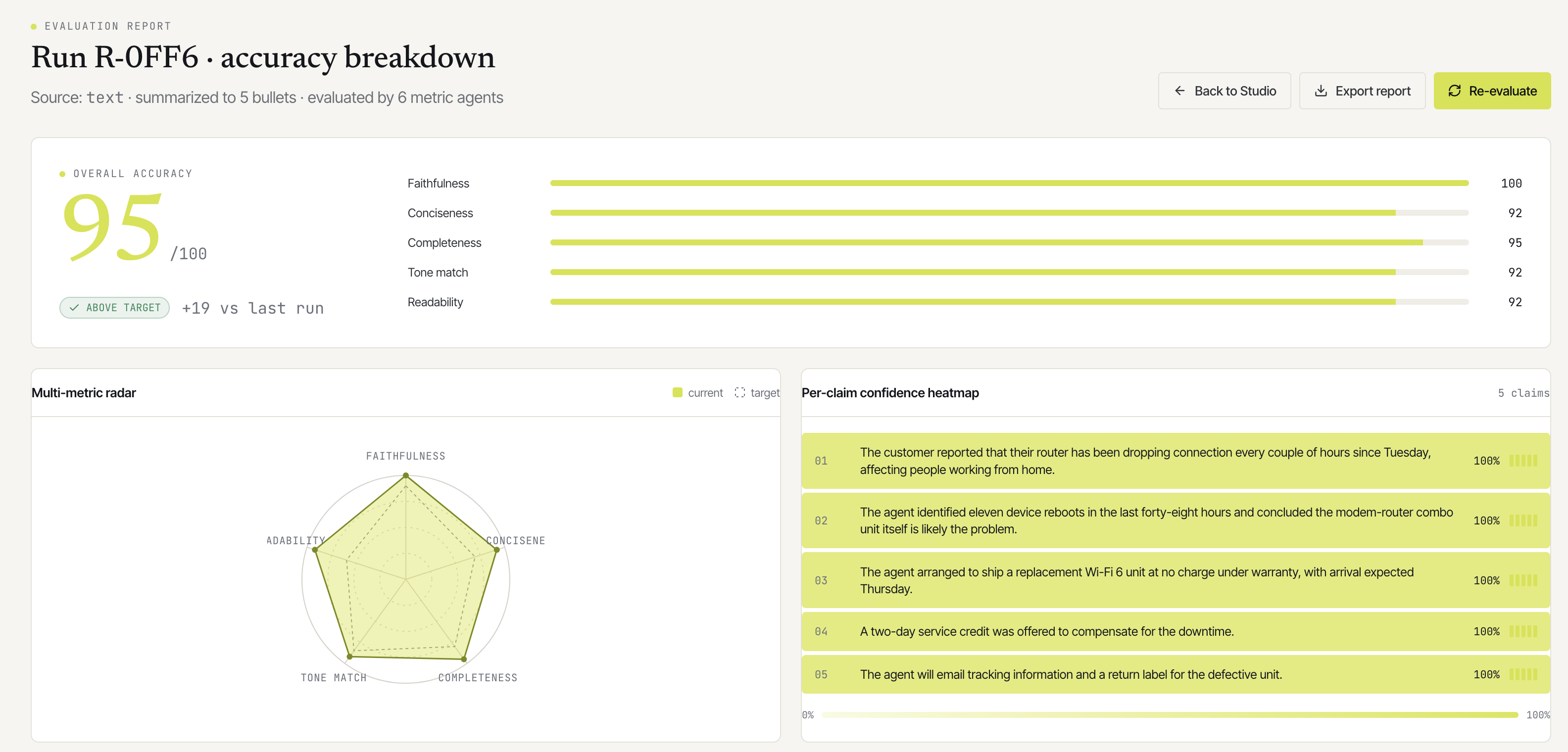
In Synapse today, all six evaluators run on Haiku 4.5. That’s been a conscious choice. The math:
| Sonnet 4.5 | Haiku 4.5 | |
|---|---|---|
| Per-call latency | ~6 to 10 s | ~3 to 6 s |
| Input cost | ~3× Haiku | baseline |
| Output cost | ~3× Haiku | baseline |
| Total eval phase | ~25 to 30 s | ~5 to 10 s |
For straightforward judgments (readability, conciseness, register match), Haiku is genuinely fine. It can tell a clear summary from a muddy one without needing 70B+ parameters. For factual claims (faithfulness, hallucination), it’s borderline. Haiku can spot obvious fabrications but occasionally misses subtle ones where a claim sounds plausible but isn’t quite what the source said.
If I were shipping the next iteration tomorrow, it would be this two-tier quality setup:
- Haiku scores all six metrics, with an additional
confidencefield on each. - If
confidence < 0.7on faithfulness or hallucination, or if Haiku’s scores contradict each other (e.g. faithfulness high but hallucination also high), escalate that specific metric to Sonnet for a second opinion. - Aggregate: if the second opinion disagrees significantly, surface both scores in the UI with a “judges disagreed” flag.
That last part matters. The point of two-tier judging isn’t to hide disagreement; it’s to surface it. If Haiku and Sonnet agree on faithfulness, confidence goes up. If they disagree, that’s exactly the run a human should inspect.
It’s worth being explicit about intent: Haiku-to-Sonnet escalation improves adjudication quality on hard cases, but it does not remove same-family bias because both are Claude-family models. Bias control is a separate stream: periodic cross-family judging and human review on persistent disagreements.
The biases nobody mentions until you trip over them
Chip’s chapter has a long catalog. The ones that bit me first:
Position bias. When you ask a judge to compare A and B, the order they appear in affects the outcome. Same content, different order, different verdict, sometimes flipped entirely. The mitigation is dumb but effective: judge each pair twice with the order swapped, and only count the result if both orderings agree.
Verbosity bias. Judges prefer longer answers. Almost universally. Two summaries with identical factual content: the longer one will score higher on “completeness” because the judge confuses length for thoroughness. In Synapse this affects conciseness in particular, where the metric is supposed to penalize verbosity but the judge’s underlying bias pulls the other way. Mitigation: the prompt explicitly instructs the judge to discount length and a length-normalization step on the raw output.
Self-preference. This one I’ve been ducking. Synapse uses Claude (Sonnet 4.5) for generation and Claude (Haiku 4.5) for judging. Same model family. Multiple papers have shown that LLM judges rate outputs from their own family higher than outputs from other families. The result: I can’t fully trust Synapse’s self-reported scores when the generator and judge are both Claude. The fix is to run a periodic cross-family validation. Generate with Claude, judge with GPT-4 or Llama 3, see how much the verdicts differ. I haven’t done this yet. It’s on the list.
Beauty bias and format bias. Confident, well-formatted, smoothly-written answers get higher scores even when wrong. Hedging and uncertainty get punished. This is the opposite of what you want from a faithfulness judge. Mitigation: prompt the judge to ignore style and assess content; better, have it list the specific evidence for and against each claim before producing a score.
Anchoring. Whatever the judge sees first in the prompt sticks. If your prompt template starts with “the summary is good in these ways…” the judge has already committed to a positive verdict. The order of evidence presented to the judge matters as much as the order of options.
The thing all of these have in common is that they’re systematic. They don’t average out. Running the same judge 10 times on the same input doesn’t fix verbosity bias; it just gives you 10 verbose-favoring verdicts. The only fixes are: change the prompt structure, change the comparison shape, or change the judge.
What I want to ship next: comparative evaluation
The highest-leverage change in Synapse’s eval pipeline is moving from pointwise to comparative scoring.
Right now, each evaluator is pointwise: “rate this summary on a 0 to 1 scale for faithfulness.” That sounds clean but it’s calibration-sensitive. What does 0.85 mean? Is Haiku’s 0.85 today the same as Haiku’s 0.85 last week? When I tweak the summarizer prompt, did the score go up because the summary got better or because the judge’s threshold drifted?
Comparative (pairwise) evaluation sidesteps this. Instead of asking “how faithful is this?”, you ask “which of these two is more faithful?” The judge no longer needs an absolute reference frame. It just needs to pick a winner.
In Synapse, this shows up in three very practical places:
- Regenerate. When the user clicks “Regenerate,” I currently produce a new summary with new absolute scores and let them eyeball the difference. With comparative eval, I’d run a head-to-head: for each metric, which version wins? The UI changes from “score went from 0.86 to 0.89” to “Faithfulness: new version wins. Conciseness: tie. Readability: old version wins.” That’s actually useful.
- Recent runs ranking. As the runs table grows, do round-robin pairwise comparisons across pairs of runs to produce an Elo-style ranking. This is exactly what Chatbot Arena does for models, applied to summaries instead.
- Prompt or model A/B tests. When I want to try a different system prompt for the Summarizer, the natural way to validate is “run both on the same 50 sources, pairwise compare, count wins.” No absolute scoring needed.
What this looks like in the code:
flowchart TB
SourceA[Run A<br/>summary + claims]
SourceB[Run B<br/>summary + claims]
subgraph PairwiseEval [Pairwise eval, per metric, ~5 s]
direction TB
Forward["Judge call 1<br/>order: [A, B]"]
Reverse["Judge call 2<br/>order: [B, A]"]
Aggregate{"Both<br/>agree?"}
end
Result[(Winner: A / B / tie<br/>confidence: 0..1<br/>rationale)]
SourceA --> Forward
SourceA --> Reverse
SourceB --> Forward
SourceB --> Reverse
Forward --> Aggregate
Reverse --> Aggregate
Aggregate -->|yes| Result
Aggregate -->|no| Tie["Tie<br/>(position bias detected)"]
Tie --> Result
The implementation is straightforward:
- A new
PairwiseJudge(metric_id, run_a, run_b)class that mirrors the existingEvaluatorclass. Samejudge()helper, structured output{winner: "a"|"b"|"tie", confidence: float, rationale: str}. - Each comparison runs twice with positions swapped. If both runs produce the same winner, that’s the verdict. If they disagree, it’s a tie (and you’ve just measured position bias).
- A new table
comparative_resultskeyed on(run_a_id, run_b_id, metric_id)so we don’t redo comparisons we’ve already made. - An Elo-style rating on the runs themselves, updated after each comparison.
The eval page gets a “Compare” tab when there’s more than one run on the same source. The Studio page’s Regenerate button kicks off the pairwise comparison in the background and shows the verdict when it completes. This is still a modest change, but not a toy one.
The reason this matters more than another pointwise metric is that pairwise eval is the thing that survives model upgrades. Today’s faithfulness scores are calibrated against today’s Haiku. When Haiku 5 ships, the calibration shifts and the absolute scores stop being comparable to the old runs. Pairwise comparisons stay valid as long as the judge can pick a winner.
Other Chapter 3 notes worth carrying forward
These didn’t fit cleanly above, but they matter if you’re building eval into a product:
Calibration. If your judge reports “0.9 confidence,” does it actually correspond to 90% accuracy on a held-out set? Almost never. LLM confidence scores are not naturally calibrated. To make them mean something, you’d run a held-out human-labeled set, plot a reliability diagram (predicted confidence vs actual correctness), and apply Platt scaling or isotonic regression to map raw scores to calibrated probabilities. I haven’t done this for Synapse. It’s a real gap.
Reference-free vs reference-based. Synapse’s faithfulness check is reference-free. There’s no “correct summary” to compare against; the source itself is the reference. That’s the right design for an open-ended summarizer. But for evaluating, say, translation quality, you’d typically want a golden reference. If I ever build a Synapse-for-known-documents (e.g. summarize this paper and compare to the abstract), reference-based metrics like BERTScore become viable and are much cheaper than LLM-as-judge for similarity tasks.
Inter-rater agreement, judge edition. How stable is a single judge across runs of the same input? Run the same source through the eval pipeline 10 times. The variance in the scores is the noise floor. If the Faithfulness score varies by ±0.1 across identical runs, you can’t report a real difference smaller than 0.1. I should be measuring this and surfacing it as confidence intervals on the eval page, not single point scores.
The judge can’t judge itself. Meta-evaluation (evaluating the evaluator) needs humans, full stop. At some point I have to label 50 to 100 summaries by hand and use that set to validate Synapse’s judges. There’s no way around it; AI-as-judge is bootstrapped on human eval somewhere up the chain. The best you can do is amortize that cost across many product evaluations.
Evaluation governance. Disagreement needs an owner and a cadence. In Synapse, any run where factual metrics escalate and still disagree (or confidence remains low) should be queued for human review, not silently averaged away. The operating rhythm I want is a weekly pass over disputed runs for prompt/rubric fixes, a monthly calibration check against the human-labeled anchor set, and a recurring cross-family bias audit on sampled runs to quantify same-family lift and drift over time.
Eval cost as a percentage of generation cost. Today Synapse’s eval phase is roughly 10% of total cost (6 Haiku calls vs 6 Sonnet calls, with Haiku being ~5× cheaper). When I add the two-tier escalation, that ratio rises. When I add pairwise eval, it rises again. There’s a budget conversation lurking: at what point does eval become more expensive than generation, and is that fine? The book’s answer is “yes, for high-stakes uses” and I think that’s right.
Specialized evaluation models. Companies like Patronus, Adam, and Scale are training eval-specific models. They’re not yet at “drop-in replacement for a general LLM judge” quality, but the gap is closing. Worth tracking. The day a specialized faithfulness judge regularly beats Haiku 4.5 at 1/10th the cost is the day I’d swap it in.
Reward models are different from judges. Both score outputs, but reward models are trained on preference data and used inside RLHF; judges are prompted and used for product evaluation. For shipping a product like Synapse, judges are the right tool. Reward models become relevant only if you’re fine-tuning a model yourself.
Where Synapse is today vs what ships next
Current state (shipped):
- Six pointwise evaluators run concurrently on Haiku 4.5 after summary generation.
- Each metric returns structured output:
{value, explanation}. - Results are persisted per run and rolled into an overall normalized score.
- Evaluation is fast enough for interactive use (~5 to 10 s wall clock).
Next state (planned):
- Add a per-metric confidence signal and use it for escalation decisions.
- Introduce two-tier quality adjudication for factual metrics: default Haiku, escalate uncertain or contradictory cases to Sonnet.
- Add pairwise evaluation for regenerate flows and prompt/model comparisons.
- Persist comparative verdicts so ranking and historical comparisons don’t require recomputation.
- Build and maintain a small human-labeled anchor set to calibrate and validate judge behavior over time.
Concrete policy (quality vs bias):
- Quality policy: escalate
faithfulness/hallucinationfrom Haiku to Sonnet when confidence is low or metric signals conflict. - Bias policy: treat Sonnet adjudication as same-family confirmation, not independence. Run cross-family re-judging (or human review) on a sampled slice and all persistent disagreements.
- Decision policy: never silently average unresolved factual disagreement; flag it and route to human review.
Closing
The biggest thing Chapter 3 reinforced for me is that evaluation isn’t a one-time step at the end. It’s the loop that decides whether the system actually improves or just gets more confident in bad behavior.
So the undervalued work in Synapse is evaluator design: which judges I trust for which tasks, where their bias shows up, and how disagreement gets surfaced instead of averaged away. Comparative eval is next because it makes run-to-run changes meaningful. Cross-family validation follows right after because same-family judging can’t answer the self-preference problem on its own.
If you’re building a system like this and you’ve read this far, the one piece of advice I’d offer is: build the human-labeled eval set you keep telling yourself you’ll get around to. Fifty hand-labeled examples is enough to anchor everything else. Without that anchor, every AI-as-judge metric you ship is calibrated against nothing.
Synapse is a personal project; full design notes in my previous post. Chip Huyen’s AI Engineering is the kind of book where you find yourself nodding through and then quietly closing a few tabs in your editor. Chapter 3 is the densest stretch on evaluation methodology I’ve read recently. Recommended.